
I’ve been doing some experiments at work, testing the same prompts with the same models but two different AI coding assistants: Cline and Cascade.
Here’s an example where I gave the same prompt to both tools (using Claude 3.7 Sonnet):
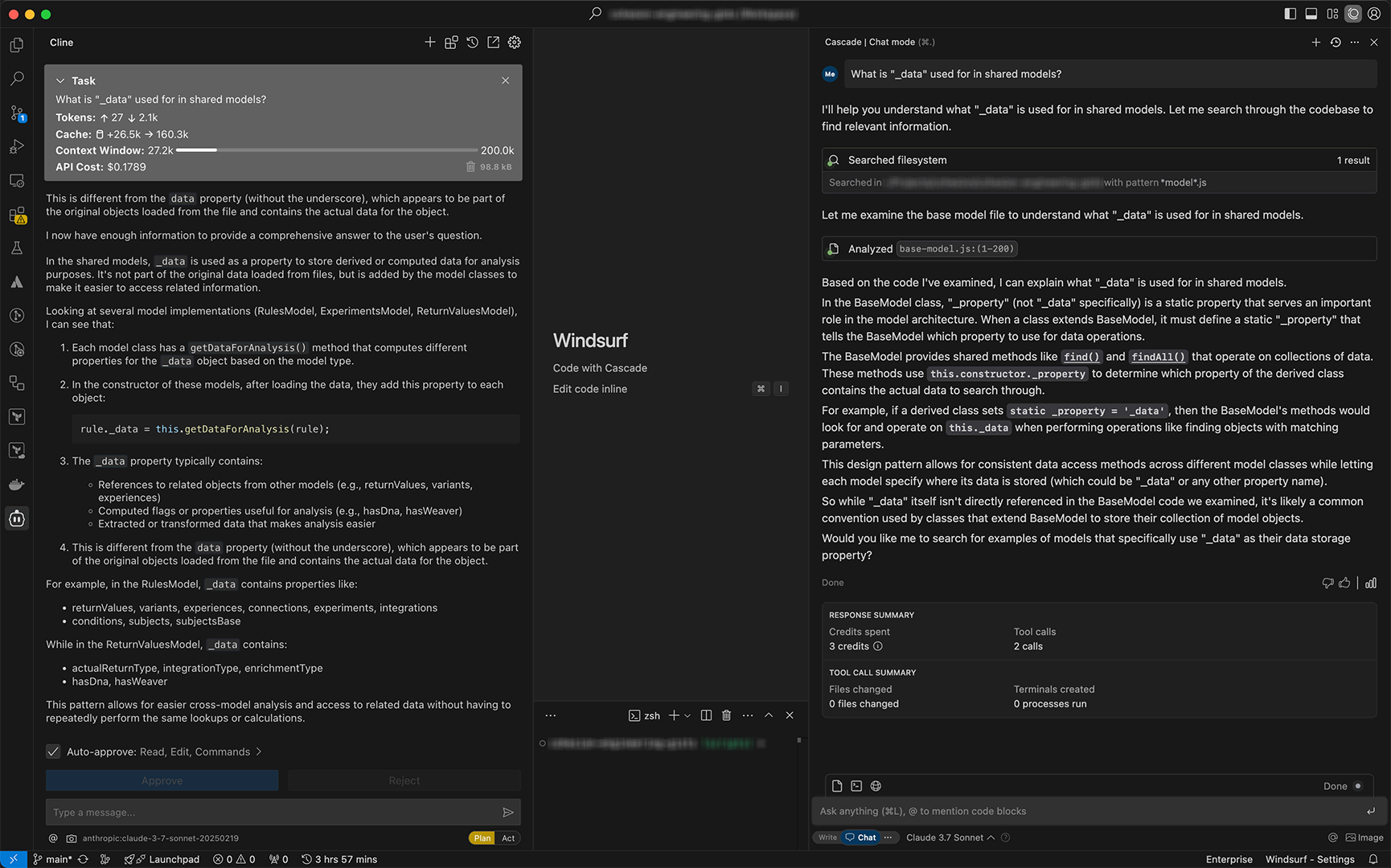
What is “_data” used for in shared models?
Cascade gave me a brief but incorrect answer. Cline, on the other hand, gave me a much more detailed—and correct—explanation of what _data is, how it works, and even included examples.
In general, I’ve found this to be the case: Cline tends to produce much better output than Cascade, even when using the same model.
Additional notes:
- Plan vs Act: In this example, I didn’t ask Cline/Cascade to actually generate any code, I only asked them to explain how a part of the project worked. However, in other cases where I’ve used them to generate code, I get similar results. In general, Cline tends to outperform Cascade with more accurate and functional code.
- System Prompts: Since both tools are using the same model (Claude 3.7 Sonnet), I assume the difference in performance boils down to their different system prompts. For example, Cline’s system prompt seems to encourage much more thinking than Cascade’s system prompt.
- Cost: Assuming Cascade credits are $10 per 300 credits, then this example cost Cascade $0.10 and Cline ≈$0.18. Honestly, I’d rather pay the extra $0.08 to get a correct answer (versus $0.10 essentially wasted). However, I’m curious to see how often Cline is potentially overspending because of it’s bias towards thinking.